
Opowiemy Wam dziś o tym, jak oswoić Słonia, czyli Apache Hadoop, dlaczego się na niego zdecydowaliśmy, co zyskaliśmy i jakie napotkaliśmy problemy. Zapewniam, że będzie to pigułka wiedzy przyswajalna także dla tych, którzy nie mają nic wspólnego z IT. Dowiecie się m.in. dlaczego warto zatrudnić słonia w komisji wyborczej, a także jak powstają nasze raporty Trends.
Skąd Sotrender ma świeże dane?
Jak wiecie w naszym narzędziu możecie monitorować profile z Facebooka, Twittera, YouTube’a oraz Instagrama. Oczywiście w naszym idealnym świecie już teraz to robisz. Pomyślcie więc, dla ilu profili sprawdzacie dane? Dla jednego? Dla pięciu? Dwunastu?
Teraz pomyślcie, że w całej naszej bazie jest obecnie ok. 30.000 profili. Wszystkie aktywnie monitorujemy, czyli informacje o nich aktualizujemy mniej więcej co godzinę. Robimy to wysyłając zapytania do API – tzw. API calls. Takich zapytań wysyłamy 7.000.000 dziennie.
Jak widzicie na ilustracji poniżej, poprzez API calls zbieramy dane, które gromadzimy (Storage) i następnie trafiają one z jednej strony prosto do narzędzia (Web), a z drugiej strony do zespołu analityków używających języka R (R).
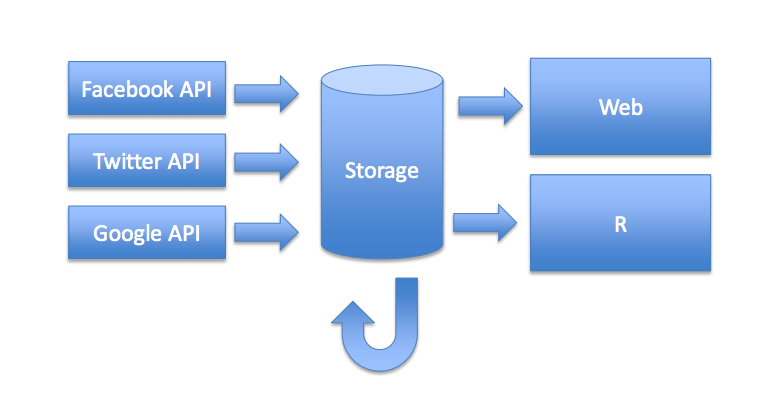
Co robi ów zespół analityków? Ich główne zadanie to realizacja nowych, niestandardowych pomysłów analitycznych i funkcjonalności, ale też to właśnie dzięki ich pracy otrzymujecie od nas raporty, w tym comiesięczne zestawienia Trends. Do tego potrzebny jest nam tytułowy Słoń – Apache Hadoop.
Czym jest Hadoop?
Przez niektórych nazywany jest Świętym Graalem Big Data. To platforma programistyczna do rozproszonego przechowywania i przetwarzania danych. Zrobiło się poważnie, więc czas na fun fact: nazwa Hadoop pochodzi od imienia pluszowego słonika, którym bawił się syn Douga Cuttinga, twórcy systemu. Wszystkim szukającym nazwy dla swojego startupu polecam ten klucz.
Nad Hadoopem pracowało od 2005 roku Yahoo (do tej pory ta firma ma największy wkład w platformę), jednak, gdy Google zdecydował się podzielić pomysłami na przechowywanie i przetwarzanie dużych ilości danych, Yahoo szybko je zaimplementowało. W 2008 roku Hadoopa przejęła fundacja Apache, ale kod tworzą głównie przez prywatne firmy.
Dlaczego warto się przesiąść na Hadoopa?
Hadoop powstał w oparciu o kilka założeń. Miał przetwarzać duże ilościach danych (mówiąc “duże ilości” mamy na myśli petabajty i eksabajty, czyli kolejno 1015 i 1018 bajtów. To naprawdę sporo, uwierzcie.), równolegle, bezstratnie, w sposób skalowalny (z reguły usługi mają wykładnicze wzrosty i z roku na rok mogą rosnąć np. kilkunastokrotnie) oraz (co ważne z perspektywy biznesu) przy użyciu względnie tanich komponentów.
Garść zalet, która przekonała nas do przesiadki z MySQL na Hadoopa:
- Elastyczne formaty danych. Możemy pracować i na różnorodnych plikach, i na bazach danych. Zdecydowana większość dostawców hurtowni danych dostarcza adekwatne współpracujące z Hadoopem wtyczki.
- Dzięki temu, że możemy “wrzucić” nieograniczoną ilość danych, nie musimy dokonywać agregacji (dane nie tracą na jakości, nawet jeśli zmieni nam się koncepcja ich wykorzystania).
- Nie musimy próbkować danych. Analizujemy cały zestaw danych.
- Nie musimy kasować danych. W naszym klastrze są dane sprzed 5 lat.
- Możemy łatwo skalować.
Nie byliśmy w tej decyzji odosobnieni, obecnie 26% dużych firm już używa Hadoopa. Zapewne znacie kilka z nich:

Kto korzysta z Hadoopa?
Fun fact rekrutacyjny: zapotrzebowanie na specjalistów Hadoopa wzrosło o 1000% względem poprzedniego roku.
Czym Hadoop różni się od relacyjnych baz danych?
Najprościej rzecz ujmując: zamiast przesyłać dane do programu, przesyłamy program do danych. Wygląda to tak:
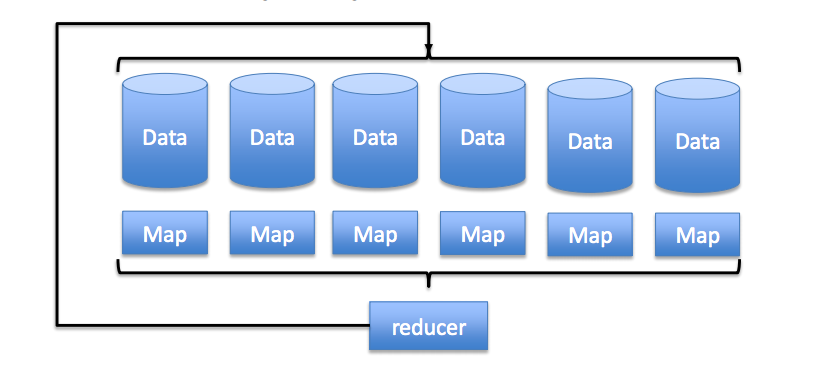
W przeciwieństwie do tradycyjnego systemu, który wyciąga dane i przetwarza je w innym miejscu, tu wysyłamy kod do każdego węzła (każdy element Data dostaje swój kawałek kodu). Potem następują obliczenia (element Map), a następnie wyniki są scalane, czyli otrzymujemy efekty naszego działania (element Reduce). Później dane wracają z powrotem do węzłów, gdzie są zapisywane.
Jak Hadoop to robi?
Mamy dwa główne komponenty Hadoopa: HDFS oraz MapReduce.
HDFS – rozproszony system plików (Hadoop Distributed File System).
HDFS powstał na identycznych założeniach, jak Hadoop, czyli miał być skalowalny (radzić sobie z gwałtownymi wzrostami), odporny na awarie, oparty na zwykłym tanim sprzęcie, obsługujący dużą ilość danych w dużych klastrach.
Aby to osiągnąć, system podzielono na dwa elementy. Część zarządczą Namenode, która – niczym smutny kierownik – nie bierze udziału w przetwarzaniu danych, ale wie np. na jakim serwerze są poszczególne pliki oraz Datanode, prosty kod służący do zapisu i odczytu danych z dysków. W procesie rozwoju pojawiły się też JournalNode (ma na celu zwiększenie wydajności Namenode’a, byłby to więc swoisty asystent naszego smutnego kierownika) oraz Zookeeper, prosta platforma do konfiguracji i synchronizacji rozproszonych procesów.
Jakie możliwości daje taki system?
- Replikacja bloków. Nasz plik podzielony jest na bloki, z których każdy jest zapisany w kilku kopiach. Ilość kopii możemy ustawić samodzielnie (wyjściowo są 3). Oznacza to, że nasze dane zostaną powielone w klastrze tyle razy, ile chcemy.
- Świadomość struktury sieci. Hadoop zna strukturę naszej sieci, więc opisane powyżej kopie plików będą rozmieszczone tak, aby jak najbardziej zwiększyć dostępność do danych i ograniczyć transfer po sieci.
- Samonaprawianie. Jeśli nasz serwer lub dysk zostanie uszkodzony, Hadoop wykryje spadek liczby kopii i automatycznie ją przywróci z pozostałych kopii na innych węzłach.
Czego potrzebujemy, by taki węzeł skonfigurować?
- Według teorii “niski i średniej klasy sprzęt”, wystarczy lepszej klasy komputer domowy, ale z naszego doświadczenia lepiej się skupić na rozwiązaniach serwerowych.
- Podstawowa wersja poradzi sobie w 8-16 GB.
- Dużo dysków. Około 12-16, im więcej tym lepiej.
- Szybkie karty sieciowe – najlepsza opcja to oddzielne sieci do wymiany danych i oddzielne sieci do pozostałych usług, aby dane można było wymieniać szybko.
- Jeśli przechowujemy dane w chmurze to dyski sieciowe zastępuje storage, który jest podłączany do naszych węzłów.
MapReduce – “biblioteka” do przeprowadzania rozproszonych obliczeń.
Poprzez MapReduce Hadoop umożliwia przeprowadzanie rozproszonych obliczeń w trzech podstawowych krokach:
- Map. Krok polega na wykonaniu operacji lokalnie, na pojedynczym rekordzie w sposób niezależny. Przykładem mapowania będzie np. podzielenie zdania na pojedyncze słowa.
- Shuffle. Krok polega na rozdystrybuowaniu pojedynczych wyników do pogrupowania. Czyli np. poszczególne słowa ze zdania zostaną przeanalizowane według wybranego klucza.
- Reduce. Krok polega na pogrupowaniu wyników. Czyli poszczególne słowa z pierwotnego zdania otrzymamy jako grupy – zgodnie z wybranym kluczem.
Jak wygląda to w praktyce? Spójrzmy na poniższy przykład:

Źródło: http://www.r-bloggers.com/an-example-of-mapreduce-with-rmr2/
Naszym celem jest zweryfikowanie, ile razy w naszych danych (Input) pojawiają się poszczególne słowa. Na samym początku system podzieli dane wejściowe na mniejsze elementy (Splitting), aby przejść do pierwszego z głównych kroków – Mappingu:
- Mapping: w tym kroku każda z linii zostanie sprawdzone pod kątem tego, ile razy występuje w niej pojedyncze słowo.
- Shuffling: takie same słowa zostają rozdystrybuowane do pogrupowania.
- Reducing: zostają utworzone grupy złożone z takich samych słów.
W ramach Final result otrzymujemy podsumowanie ilości wystąpień poszczególnych słów. Dokładnie to samo w podobnym tempie stałoby się, gdyby nasz Input zawierał miliard wierszy.
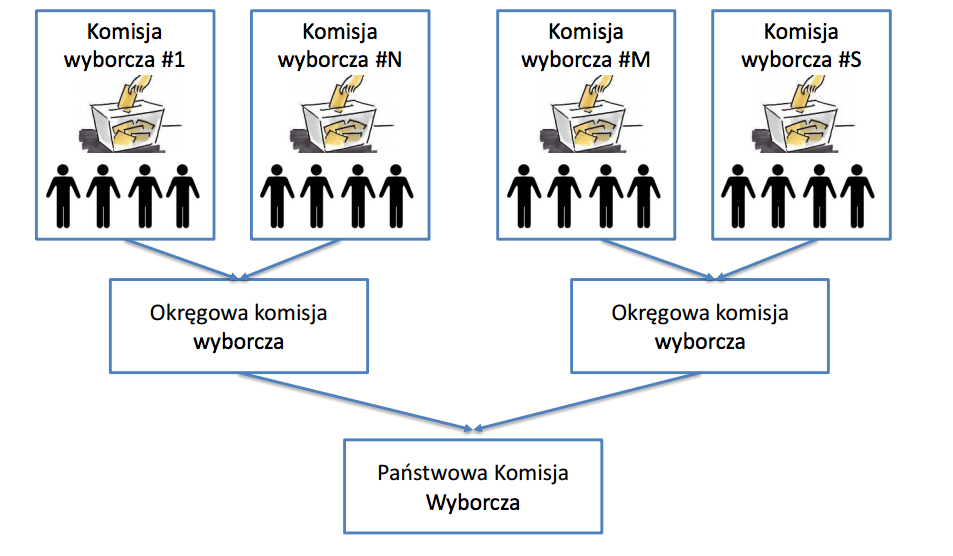
Słoń w komisji wyborczej.
Przykłady takiego podejścia znajdziemy w naszym codziennym życiu. Dobrym jego zobrazowaniem są wybory i sposób zliczania głosów, gdzie również stosowane jest podejście MapReduce.
- Mapping: jednostki wykonawcze – członkowie komisji wyborczych, zliczają pojedyncze głosy.
- Shuffling: następuje redystrybucja głosów oddanych na poszczególne partie.
- Reducing: zostają utworzone grupy złożone z głosów oddanych na te same partie.
Państwowa Komisja Wyborcza może pracować sprawnie dlatego, że otrzymuje pogrupowane informacje o wynikach z mniejszych jednostek, a nie zostaje zalana dwudziestoma milionami głosów.
Hadoop w Sotrenderze
Początki – MySQL.
Nasze działania zaczynaliśmy na MySQL, od jednego serwera. Dodając co kilka miesięcy kolejne i coraz mocniejsze, doszliśmy do 6 maszyn. Jednak była to droga nieefektywna, nieskalowalna, wymagająca coraz to większej ilości maszyn, co przełożyłoby się na problemy z migracją danych. Ponadto przy awariach MySQLa naprawy były czasochłonne, nie wspominając o przerażającej liczbie zmiennych konfiguracyjnych.
Hadoop okazał się dla nas rozwiązaniem problemu składowania i przechowywania danych. Obecnie aktywnie korzystamy z HBase i Hive do zbierania i przetwarzania naszych zbiorów danych. Wykorzystujemy też innne rozwiązania z rodziny Hadoop takie jak Spark czy Solr.
Gdzie znajdziecie wykorzystanie Hadoopa w Sotrenderze
Zespół analityków pracujący w R wykorzystuje Hadoopa przede wszystkim do niestandardowych raportów realizowanych na życzenie klientów. Ale każdy z Was miał na pewno okazję zetknąć się z Trendsami. One także powstały “dzięki” tej platformie!

Materiał został przedstawiony przez Pawła Kucharskiego, współzałożyciela i CTO Sotrendera podczas AnalyticsConf 2015. Całość prezentacji znajdziecie tutaj: część 1 i część 2.


